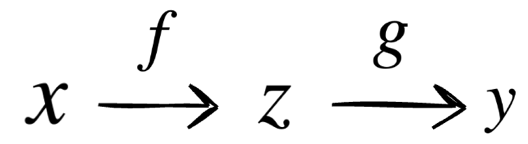Modern neural networks often consist of multiple layers and a large number of parameters, sometimes reaching millions. The central challenge in training such networks is determining how to efficiently update these parameters so that the model’s predictions improve over time. This learning process is achieved through an algorithm known as backpropagation, which systematically computes gradients of the loss function with respect to each parameter in the network.
Build Intuition of Chain Rule of Calculus
Consider we have a function  g(f(x))
Chain Rule of Calculus (scaler case):
Consider,
z=f(x)=x2
y=g(z)=ez=ex2
We can calculate dzdy and dxdz easily.
dzdy=ez,dxdz=2x
But how would you calculate dxdy here? We have to apply chain rule here.
dxdy=dzdy.dxdz=ez.2x=ex2.2x
Chain Rule of Calculus (vector case):
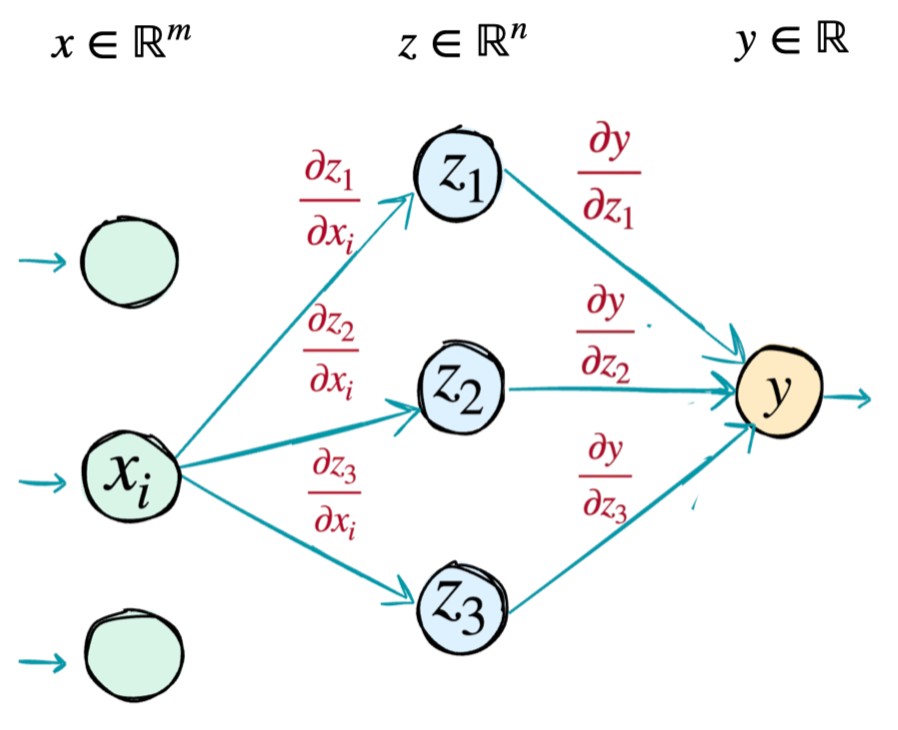
Here each zi is a function of
x=x1x2..xm
and y is a function of z=z1z2..zn. So how do we calculate ∂xi∂y for any xi?
Now to understand it simply, earlier for scaler case we just had only one path from x to z to y (x→z→y). Now for vector case here we have three paths from xi to y (considering n=3). So we have to apply chain rule in all the three paths and take the summation.
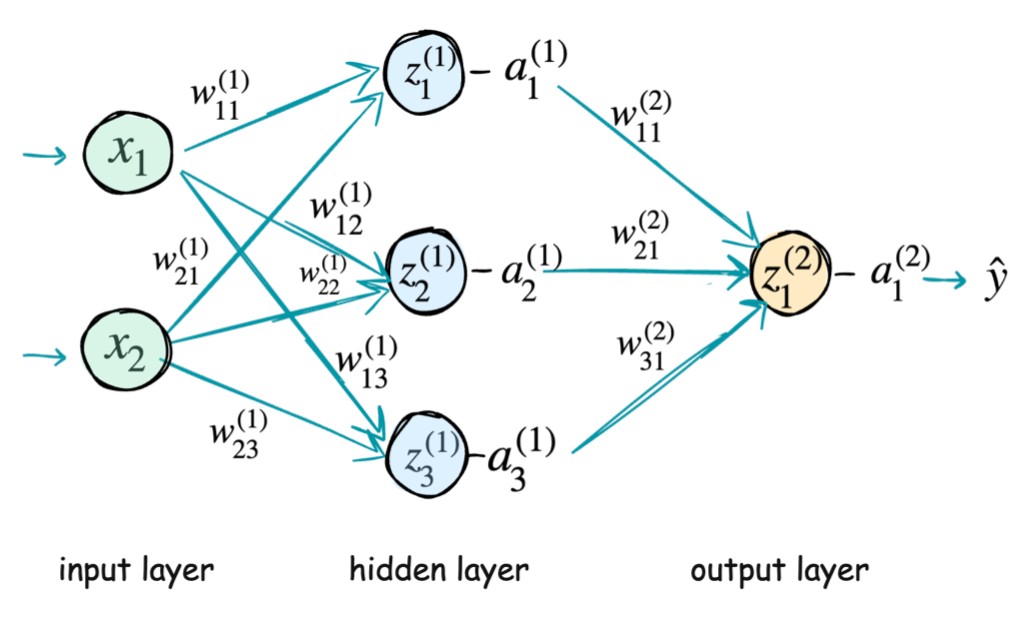
We want to train the model, that means we came up with the neural network model structure but we want to find the optimized weight parameters here. Weight parameters are named as wij(l) and it means the weight from node i from previous layer to node j in the current layer and current layer is l (starting from the first hidden layer).
How do we find the optimizer proper weights? We run Gradient Descent algorithm and weight parameters are updated in each iteration.
wt+1=wt−α∂wt∂E
wt contains all the weight parameters wij(l).
So at each iteration, our target is to find ∂wij(l)∂E for all the weight parameters.
What is E here?
E is the Error or Loss we found comparing the actual output (y) and predicted output (y^).
Loss/Error Functions
There are various types of Loss/Error functions depending on the task we want to perform. Here are few examples..
Mean Square Error(MSE)
Used mostly in linear regression problems.
E=n1i=1∑n(yi−yi^)2
Root Mean Square Error(RMSE)
Just taking square root of Mean Square Error
E=n1i=1∑n(yi−yi^)2
Mean Absolute Error (MAE)
Sum of absolute differences between actual and predicted outputs
E=n1i=1∑n∣yi−yi^∣
Binary Cross-Entropy
Used in binary classification
E=−ylog(y^)−(1−y)log(1−y^)
Categorical Cross-Entropy
Used in multi-class classification when outputs are represented as one-hot encoding format and there are K classes
E=−k=1∑Kyklog(yk^)
Sparse Categorical Cross-Entropy
Used in multi-class classification when outputs are represented with class indices (1,2,..K), y is the correct class index and y^y is the predicted probability of correct class y
E=−log(y^y)
Backward Propagation of Errors
Now we will see how we calculate the gradient of the error (or loss) with respect to all the weights. We start from the output layer and move back towards the input layer.
We are considering binary cross entropy loss for our discussion here.
E=−ylog(y^)−(1−y)log(1−y^)
Output Layer Gradients
δy^δE=−y^y−1−y^1−y(−1)=−y^y−1−y^y−1
As a1(2)=y^,
δa1(2)δE=δy^δE
Now assume a1(2) uses sigmoid activation function or a1(2)=σ(z1(2)).
We already know how to calculate the derivative of sigmoid [ σ′(a)=σ(a)(1−σ(a))]
δz1(2)δa1(2)=σ(z1(2))(1−σ(z1(2)))
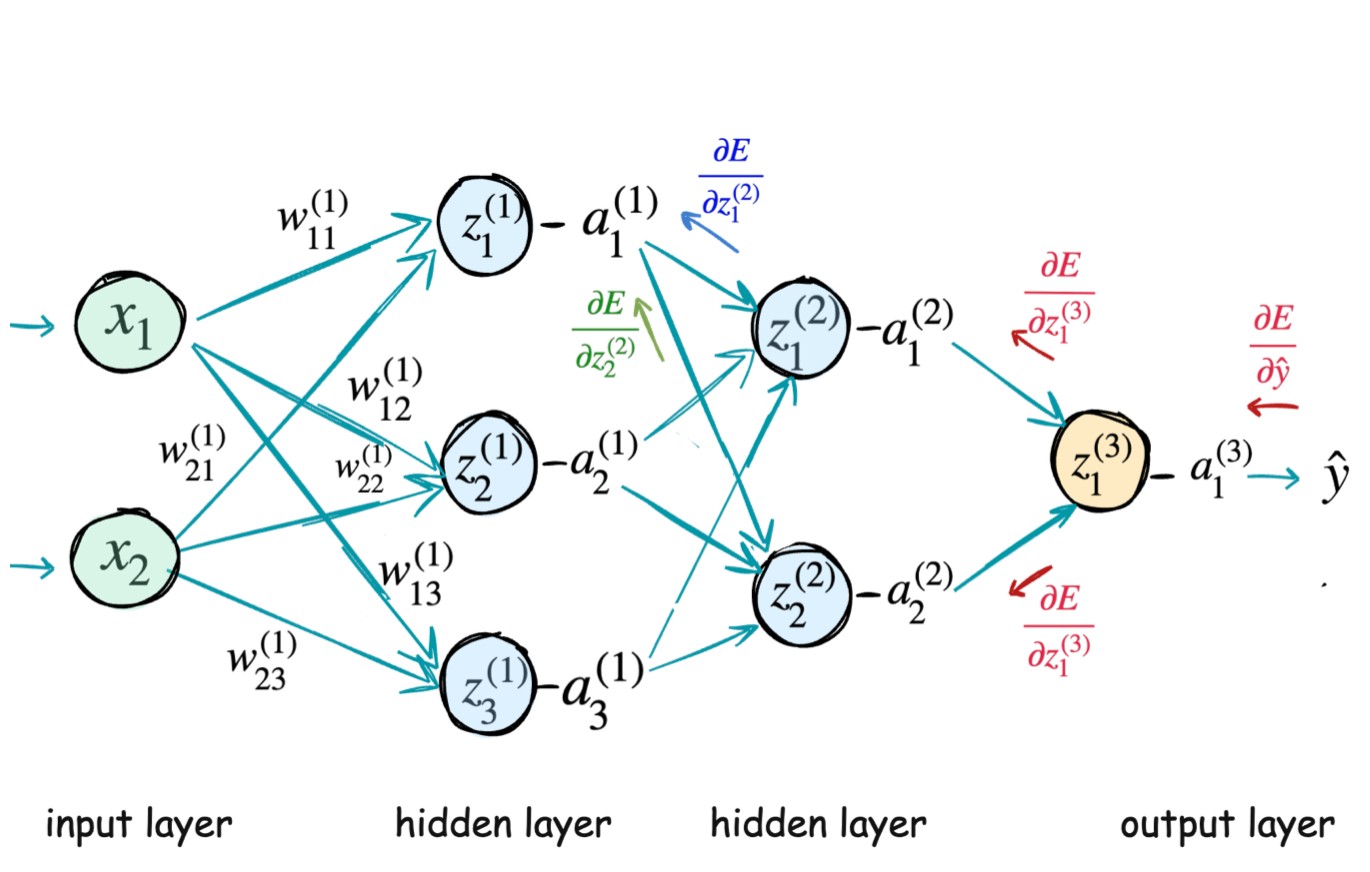
Now how do we calculate δz1(2)δE? We have to apply chain rule.
Here z1(2) is the linear weighted combination of previous layer neurons. Also, biases ( like w01(2) ) are not shown in the diagram so you just assume they are there :)
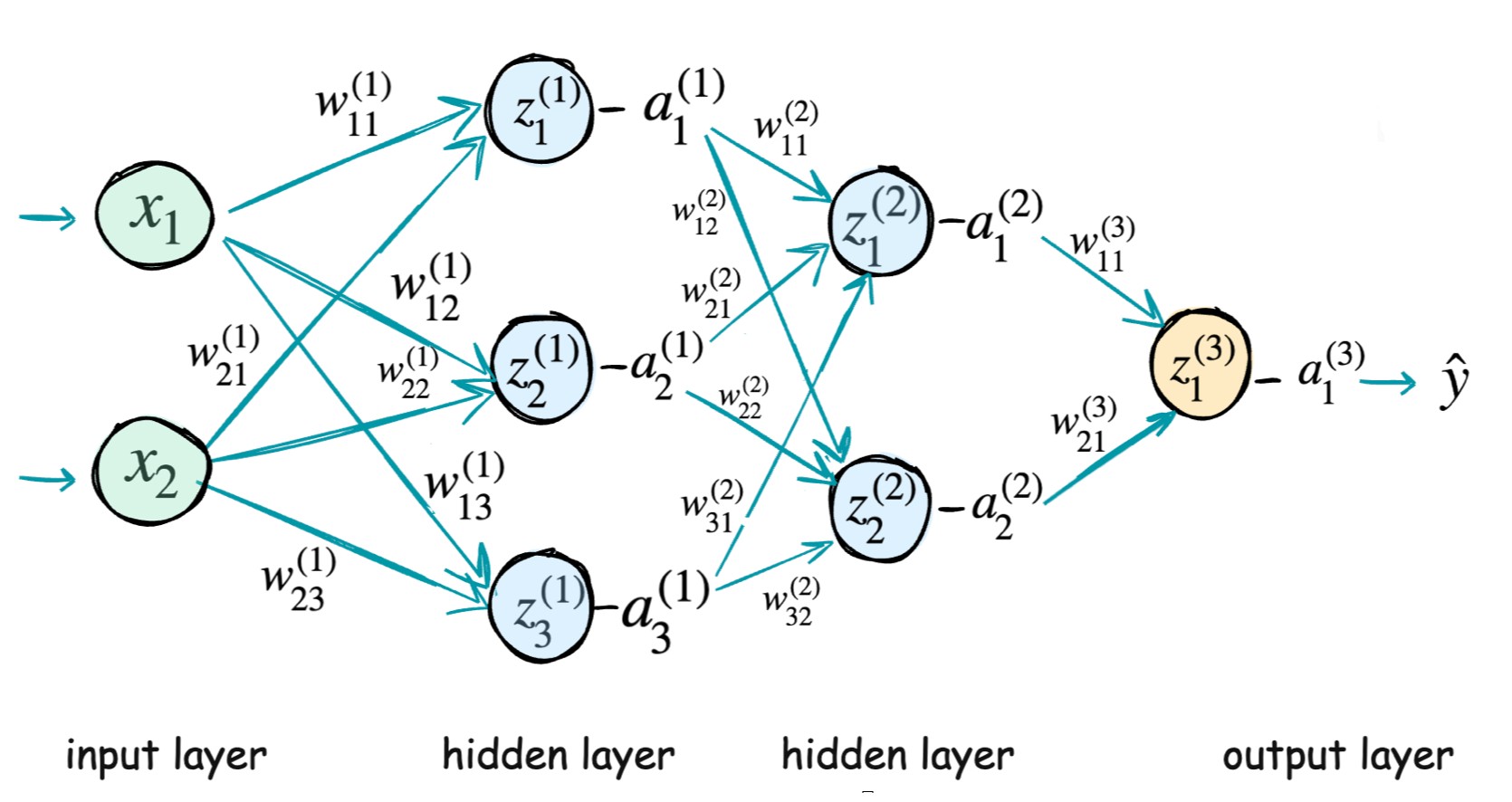
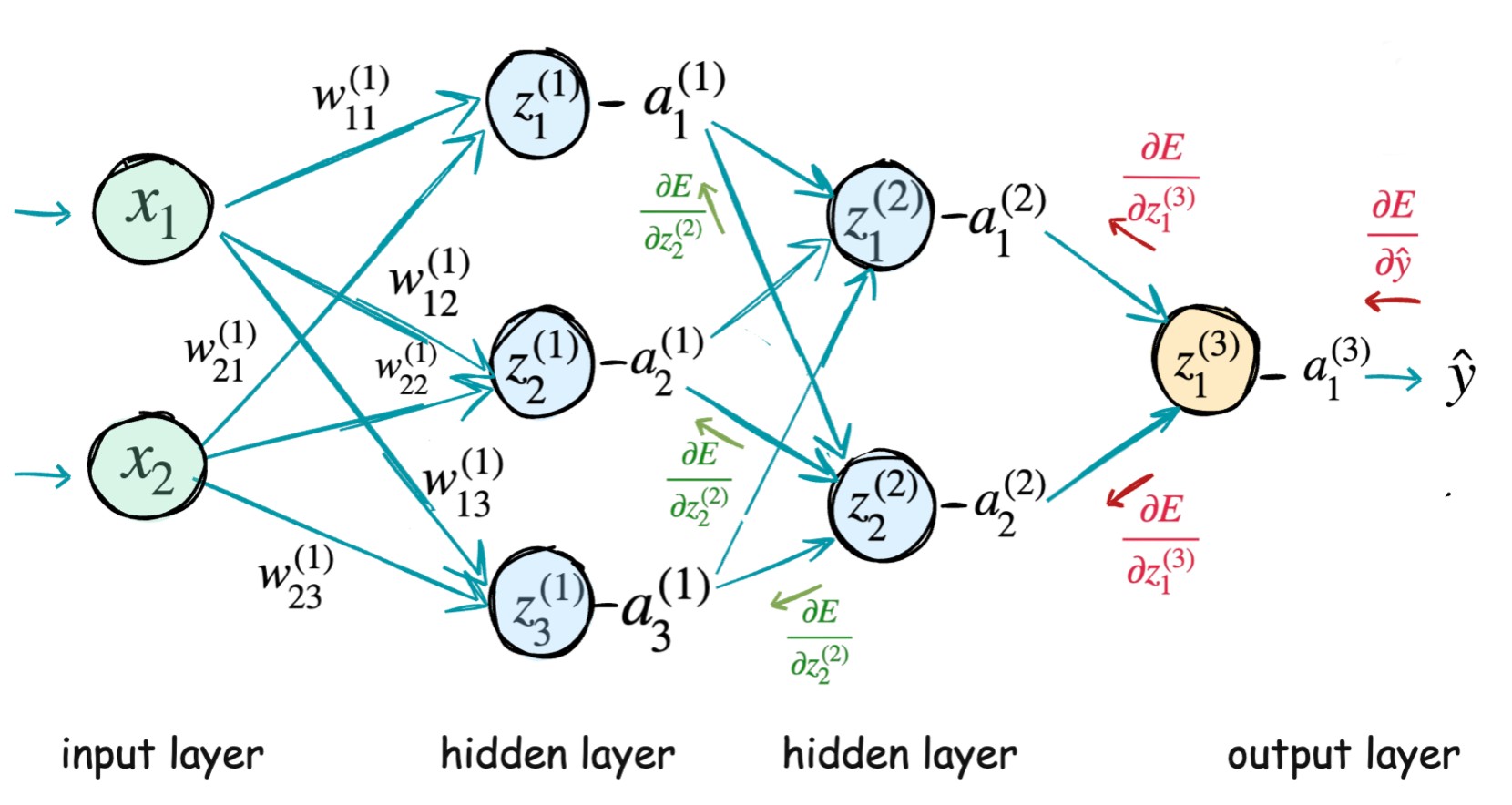
Here we are considering a different network with two hidden layers and we will see how error gradients are flowing backward from output layer to input layers.
Here z1(3) is a combination of a1(2) and a2(2). So ∂z1(3)∂E will flow in both the path as shown in the image.
∂z1(2)∂E will flow backward to three paths corresponding to a1(1), a2(1) and a3(1). Similarly, ∂z2(2)∂E will also flow backward to three paths corresponding to a1(1), a2(1) and a3(1).
How do you calculate ∂a1(1)∂E? a1(1) is influencing both z1(2) and z2(2). The error ∂z1(2)∂E and ∂z2(2)∂E both backpropagating towards a1(1).
So we have to apply vector case for chain rule of calculas..