Feature Extraction in Natural Language Processing
Feature extraction in NLP is the process of converting raw text into numerical representations that machine learning models can understand. Since models cannot work directly with human language, feature extraction acts as a bridge between text and algorithms by transforming text inputs into a set of numbers, usually represented as vectors. This step is crucial because text data is unstructured, high-dimensional, and highly context-sensitive. Without effective feature extraction, NLP models struggle to learn meaningful patterns, whereas good feature representations help improve accuracy, reduce noise, and capture semantic meaning.
Traditional Feature Extraction Techniques in NLP
One-hot vector representation
Here we will represent every word as a dimensional vector, where is the size of the vocabulary. In the vocabulary every word will have one position associated with it, starting from to . In the size vector, only in the place of that position we will have , rest are zeros. We are denoting the vector corresponding to word as .
If “aardvark” and “abacus” are the first and second words and “zyzzyva” is the last word in the vocabulary, then their one-hot representation will look like below.
Advantages
-
Simple and intuitive
-
Unique vector representation for each word**
-
It works well for small datasets and as a starting point for NLP models.
Limitations
-
High dimensionality
The dimensionality of a one-hot vector is equal to the size of the vocabulary.
For large corpora, the vocabulary size becomes very large, leading to high-dimensional vectors. -
Sparse representation
One-hot vectors are extremely sparse, with only a single1and the rest of the values being0.
A corpus containing documents and a vocabulary of size results in a sparse matrix of size . -
No context awareness
Each word is treated independently of others.
For example, the phrase “New York” has a specific meaning, but one-hot encoding represents “New” and “York” as unrelated words. -
No notion of semantic similarity
Word vectors of related words are not close to each other in vector space.
Since one-hot vectors are orthogonal, their dot product and cosine similarity are always zero.even though apple and orange are both fruits.
Bag of Words (BoW)
The Bag of Words model represents text based on word frequency, ignoring grammar and word order. It’s called Bag of Words because the model treats text like a bag (or collection) of words, where order, grammar, and structure are thrown away, and only the presence or frequency of words is kept. Let's try to understand with a small example below.
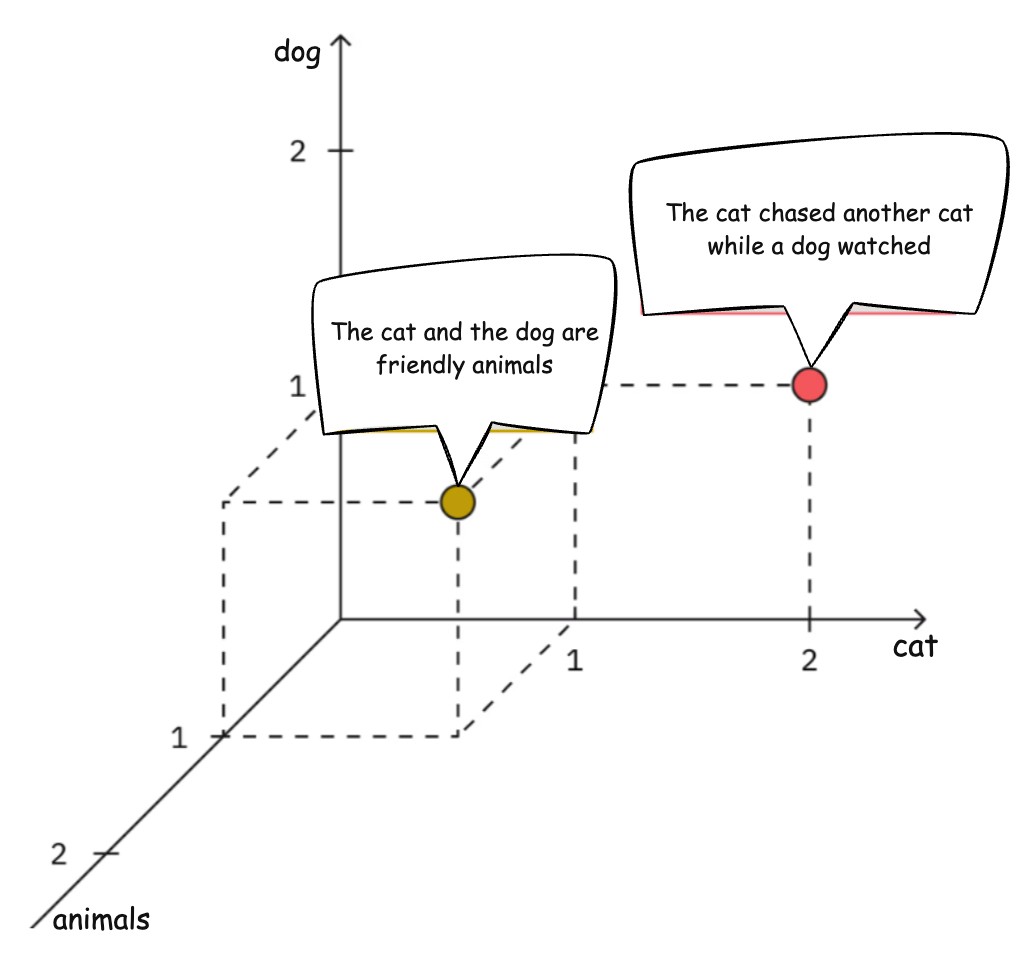
Assume the vocabulary (dimensions) contains only three words: cat, dog and animal
Document 1: The cat and the dog are friendly animals.
Word counts: cat → 1, dog → 1, animals → 1
Vector: (1,1,1)
Document 2: The cat chased another cat while a dog watched.
Word counts: cat → 2, dog → 1, animals → 0
Vector: (2,1,0)
Bag-of-Words can be represented as a weighted summation of the one-hot encoding vectors in a document. Let’s Consider there are words in the document and we denote the one-hot vector representation for word as . Here the Bag-of-words representation of the document , let’s say we call it , will take a weighted sum of the word vectors.
Here the weights s can be the frequency of the words in the document.
For the Document: The cat chased another cat while a dog watched
Word counts: cat → 2, dog → 1, animal → 0
Hence,
Advantages
- Simple and fast
- Effective for small datasets
Limitations
-
Ignores word order (loss of meaning)
Sentences such as “cat eats fish” and “fish eats cat” have the same Bag-of-Words representation, even though their meanings are completely different. -
High dimensionality
-
Sparse feature vectors
N-grams
In addition to the vocabulary, we can take bigram(two words at a time) or trigram ( 3 words at a time) or n-gram. Like in the sentence of “cat eats fish” we can take the bigrams “cat eats” and “eats fish”, or we can take trigram “cat eats fish”. So these two sentences “cat eats fish” and “fish eats cats” won’t be represented by the same vector as their bigrams/trigrams will be different. N-grams capture sequences of words to preserve local context.
Examples:
- Unigram:
deep - Bigram:
deep learning - Trigram:
deep learning models
N-grams improve performance for tasks like sentiment analysis but the vocabulary size will increase a lot to consider bigrams and trigrams, so this does not look like a good solution. Also, the relationship among the words are not captured here.
TF-IDF (Term Frequency–Inverse Document Frequency)
TF-IDF assigns importance to words based on:
- Frequency of a word in a document (TF -term frequency)
- Rarity across the corpus (IDF - Inverse document frequency)
This representation is a statistical measure used to evaluate the importance of a word in a document relative to a collection of documents. Each word or token is referred as a term here. The calculation is done by multiplying the Term-Frequency and Inverse-Document-Frequency of the term in the entire corpus. Let’s consider the entire corpus contains documents ( for ).
Term-frequency TF()
Term-frequency for a term in the document defines the importance of term in the document .

Inverse-Document-Frequency IDF(t, D)
Let’s say our corpus has 10000 documents and 100 of the document contains term . Then DF or document frequency of term is 100. The more number of document contains the term, the more common it is. Like the term “the” will be present in almost all the documents. So it should not be given that much importance. Hence we calculate inverse document frequency.

TF-IDF()
Now the TF-IDF is the product of term frequency and inverse document frequency.
This reduces the impact of common words and highlights meaningful terms. TF-IDF remains a strong baseline for many NLP tasks.
Limitations of Traditional NLP Feature Extraction
- Treat words independently
- Mostly High Dimensional
- Cannot capture word meaning
- Fail to handle polysemy (the coexistence of many possible meanings for a word or phrase)
Example:
"bank of the river"
"bank account"
Both sentences treat bank identically in BoW or TF-IDF models.
Motivation for better Feature Extraction
Consider a word embedding which maps words to dense, low-dimensional spaces where similar words are positioned closer together. Here each element of the word vector denotes some feature of the word, like one feature can be if it is a pet animal, another can be how much the word refers to technology etc. However, these are just for our understanding purposes. Computers won’t necessarily understand this type of features that human understands. But if we use deep learning to extract features, models should be able to generate similar feature vectors for the words.
If we have such representation, then vector calculations like additions or subtractions will be possible.
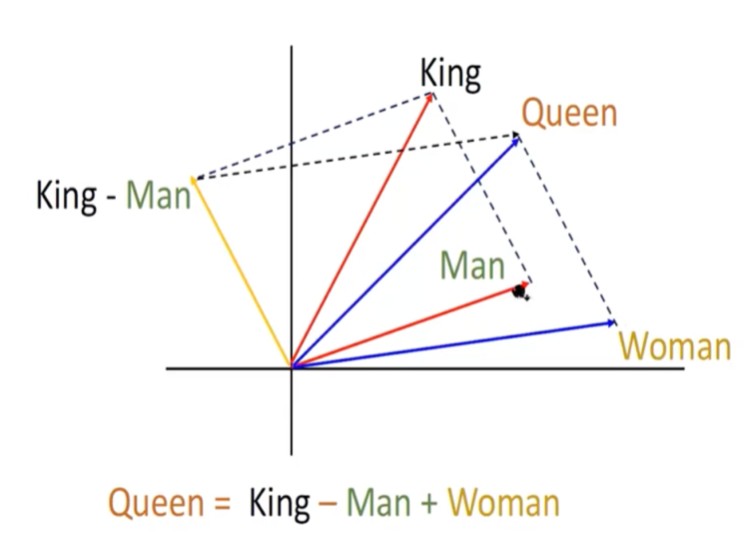
If we see the vectors here in the 2D space above, ‘Man’ and ‘Woman’ are close and similar to each other. Similarly, king and queen are close to each other. If we add ‘King - Man’ and ‘Woman’ we should get a vector close to ‘Queen’.
Looks cool isn’t it?
Let's see few other examples:
Consider a simple such vector representations here, We are considering the attributes power, rich, technology, gender in a 4-dimensional space.
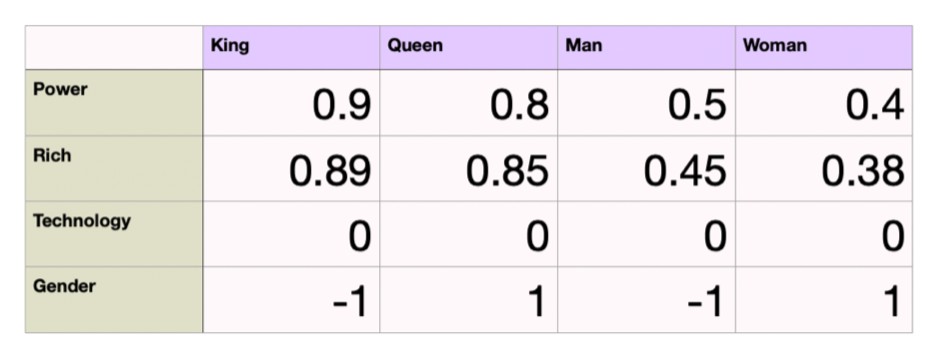
King and Queen both will have power and will be rich, hence have higher values. Nothing is related to technology here hence it is 0 for technology attribute. Gender is denoted as -1 for male and 1 for female.
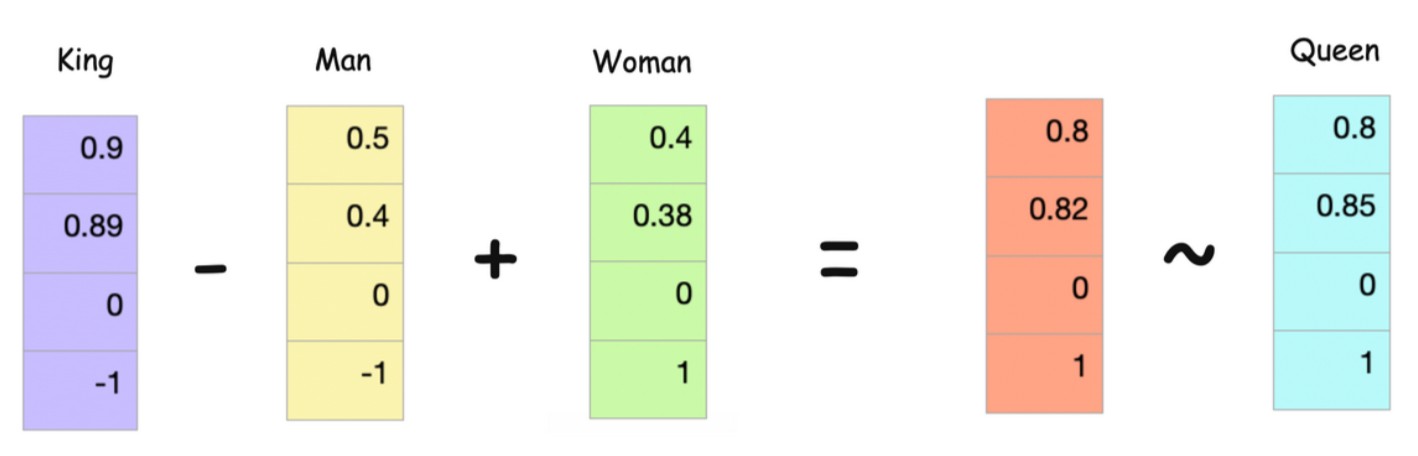
These attributes are for our understanding, computers can find out some random set of attributes. Now what we want is somewhat like below. King - Man + Woman should almost be equal to Queen.
Feature Extraction Using Word Embeddings
Word2Vec
Word2Vec learns dense vector representations using deep learning, where semantically similar words are closer in vector space.
Key ideas:
Words with similar contexts have similar embeddings.
Similar words tend to occur together and will have similar context
Here the term ‘similar’ does not mean two words need to be synonyms, rather it means they can be related.
Let’s consider the example below where centre word ‘fox’ is shown in red and its context words for different window size is shown is blue.
The quick brown fox jumped over the lazy dog. [window size = 0]
The quick brown fox jumped over the lazy dog. [window size = 1]
The quick brown fox jumped over the lazy dog. [window size = 2]
The number of words in the context on the left size is equal to the number of words on the right side. There are two main models here that we will train and as a result of that we will get our word embeddings.
- Skip-gram model: Predicts context words within a certain range before and after the current centre word in the same sentence.
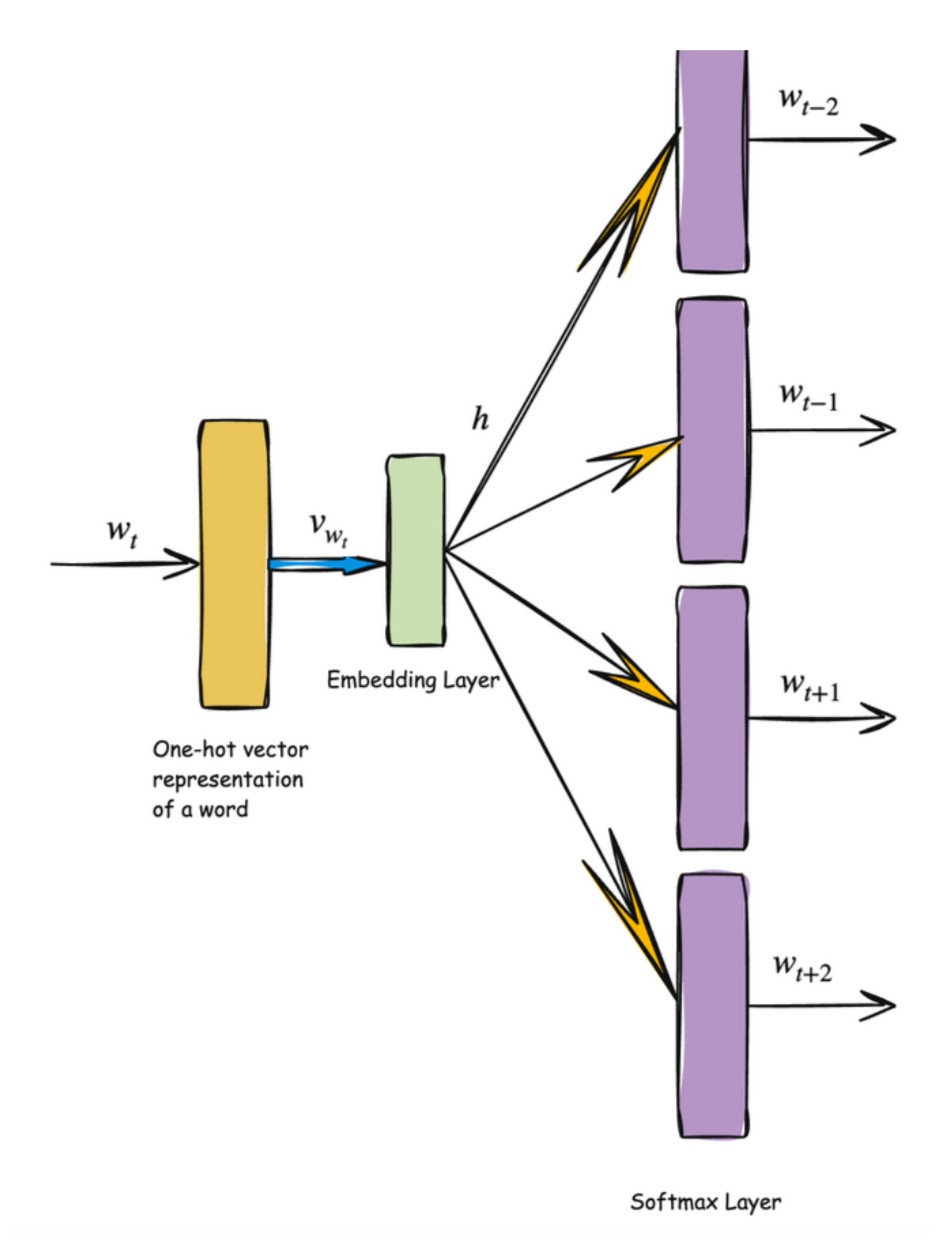
- Continuous bag-of-words model: Predicts the centre word based on surrounding context words. The context consists of a few words before and after the current (centre) word.
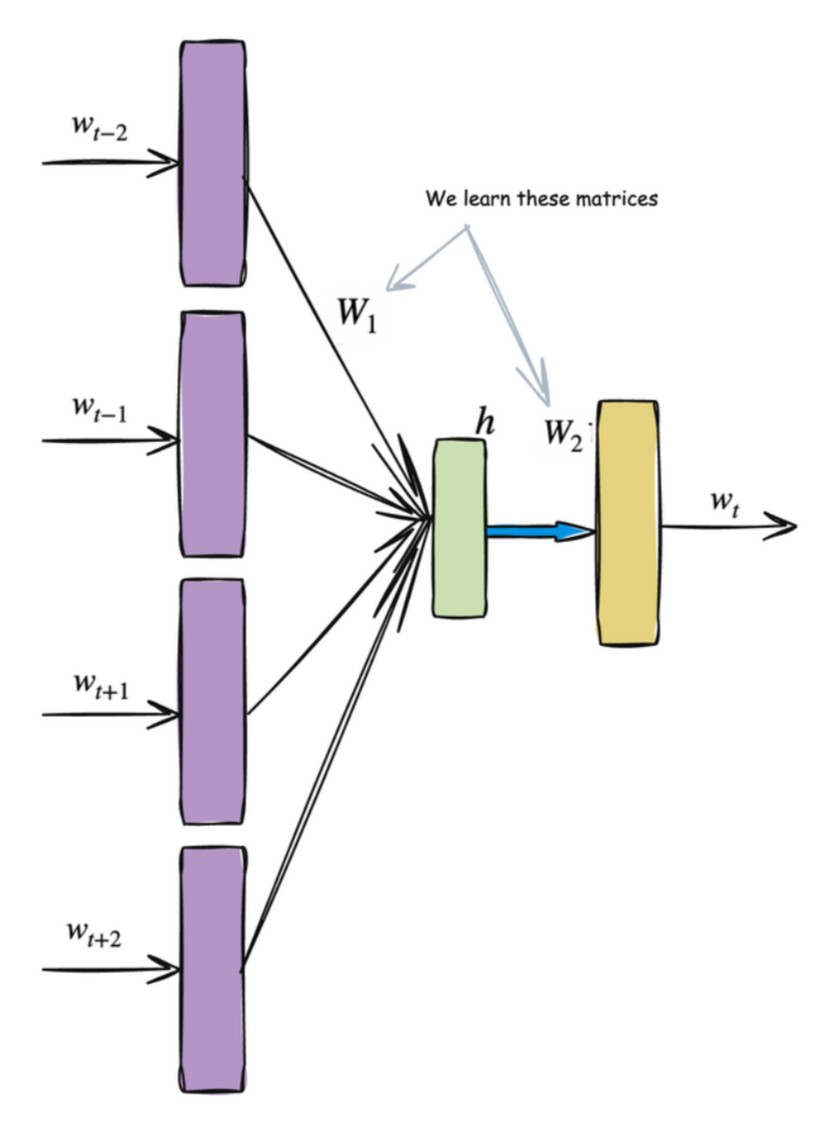
One thing to mention here, predicting context words or centre word is a fake problem we are solving here. And as a result of that we will be getting our word embeddings from the Embedding Layer(shown later).
GloVe
GloVe (Global Vectors) combines global corpus statistics with local context to produce stable embeddings. The key intuition behind GloVe is:
The meaning of a word can be derived from how often it co-occurs with other words in the entire corpus.
GloVe builds a word–word co-occurrence matrix, where each entry represents how frequently two words appear together within a fixed context window.
From this matrix, GloVe learns word vectors such that relationships between words are captured through ratios of their co-occurrence probabilities, allowing semantic meaning to emerge.
Benefits and Limitations of word embeddings
Benefits
- Dense representations
- Semantic similarity
- Better generalization
Limitation
- One vector per word
- no context-aware representation of word (like word 'bank' will have same vector for river bank and bank account)
Contextual Feature Extraction in NLP
In natural language, the meaning of a word is not fixed—it depends on the context in which the word appears. Traditional word representations assign a single vector to each word, which fails to capture this variability. Contextual feature extraction solves this problem by generating word representations that adapt based on surrounding words.
Contextual Embeddings (ELMo, BERT)
Contextual embeddings produce different vector representations for the same word depending on its usage in a sentence.
Consider the word bank:
- She deposited money in the bank → financial institution
- He sat on the bank of the river → geographical location
A contextual model assigns different vectors to bank in each sentence, even though the word itself is the same. This allows the model to distinguish meanings that traditional embeddings cannot.
Models like ELMo and BERT achieve this by analyzing the entire sentence and learning representations that encode:
- Syntax – grammatical roles and sentence structure
- Semantics – meaning of words and phrases
- Long-range dependencies – relationships between words that may be far apart in the sentence
Instead of learning a single word vector, these models learn a function that maps a word and its context to a vector representation.
Transformer-Based Feature Extraction
Modern contextual embeddings are built using the Transformer architecture, which relies on self-attention.
Self-attention allows each word in a sentence to:
- Compare itself with every other word
- Determine which words are most relevant for its meaning
- Weights information dynamically based on context
As a result, a word’s representation is influenced by the entire sentence, not just nearby words.
Why Transformers Dominate NLP
Transformers dominate NLP because they combine expressive power with scalability:
-
Automatic feature learning
Features are learned directly from data, removing the need for manual feature engineering. -
Deeply context-aware representations
Each word embedding adapts to sentence-level meaning. -
Strong modeling of global dependencies
Long-range relationships are captured efficiently through attention. -
State-of-the-art performance
Transformers achieve top results across tasks such as translation, summarization, question answering, and text classification.
In modern NLP, understanding language is no longer about counting words—it is about learning context-aware representations through attention.