Uber System Design
Functional Requirements
- rider searches for cab (with source & destination)
- uber shows ETA and fare estimate for different types of cab (go, moto, sedan etc)
- rider books a cab
- uber matches nearby drivers
- uber sends request to nearby drivers -> sends notification
- driver accept/deny ride request
- driver accepts - navigates to pickup location
- after pickup (using otp) driver navigates to drop location
- driver ends the trip
- rider makes payment
out of scope
- profile creation
- ratings( driver and rider)
- notification service
- monitoring
- analytics
Non Functional Requirements
- Cap theorem - highly available for ETA, fare estimate etc
- Highly consistent for driver matching - no double booking (1 ride two drivers, 1 drivers two ride)
- Latency - as low as possible
- durable - ride details persistence
- scalable - for peak hours, for new users
Entities
- rider
- driver
- estimate
- ride
- location
- cab
APIs
get fare estimate
GET /estimates?src_lat={}&src_long={}&dest_lat={}&dest_long={}
-> estimateId, estimate, ETA for different cab types
book a ride
POST /rides
{
estimateId,
cabType
}
location updates
POST /location/update
{
latitude,
longitude
}
driver accepts/deny ride request
patch /rides/driver/accept
{
rideId,
accept (true/false)
}
driver updates the ride for pickup and dropoff
patch /rides/driver/update
{
rideId,
update (pickedUp/droppedOff)
}
make payment
POST /payments
{
rideId,
paymentInfo {}
}
Scale
- 100 million total riders
- 10 million daily active riders - 2 riders per users (on an average)
- 1 million drivers
ride requests = 20 million per day = 20 * 10 ^6/10^5 = 200 TPS
peak TPS = 3x = 600 TPS
location update every 5s -> 10^6/5 TPS =>200k TPS
High Level Design
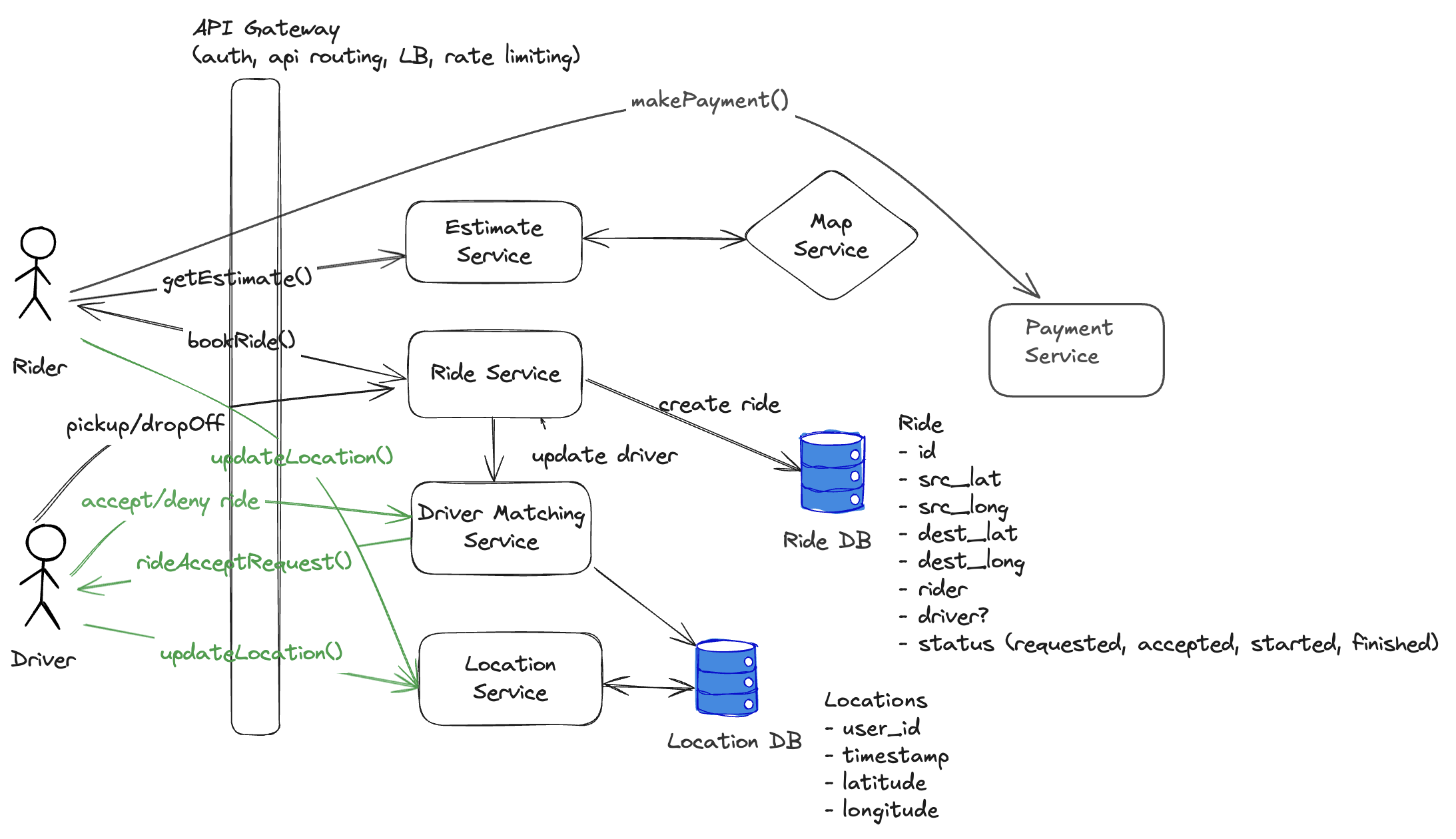
Why we need websocket connection?
- frequent location updates
- server to send ride accept requests to the drivers
- server to send real time updates for ride status update (using notification service might add delay)
why not use SSE?
- SSE not supported in all mobile devices
- websocket has lower latency
- bidirectional connection is required
So we can utilize a bidirectional connection like websocket
Handle frequent driver location updates
-
1 million DA drivers
-
sending update every 5s -> 10^6/5 TPS =>200k TPS
-
SQL database supports max 10k TPS (single node)
-
dynamoDB supports upto 100k +
-
redis supports upto 1 million TPS
-
can we do batch updates to database to reduce write overhead?
-
it introduces delay in driver location updates -> driver matching might not be appropriate
Driver Matching Logic
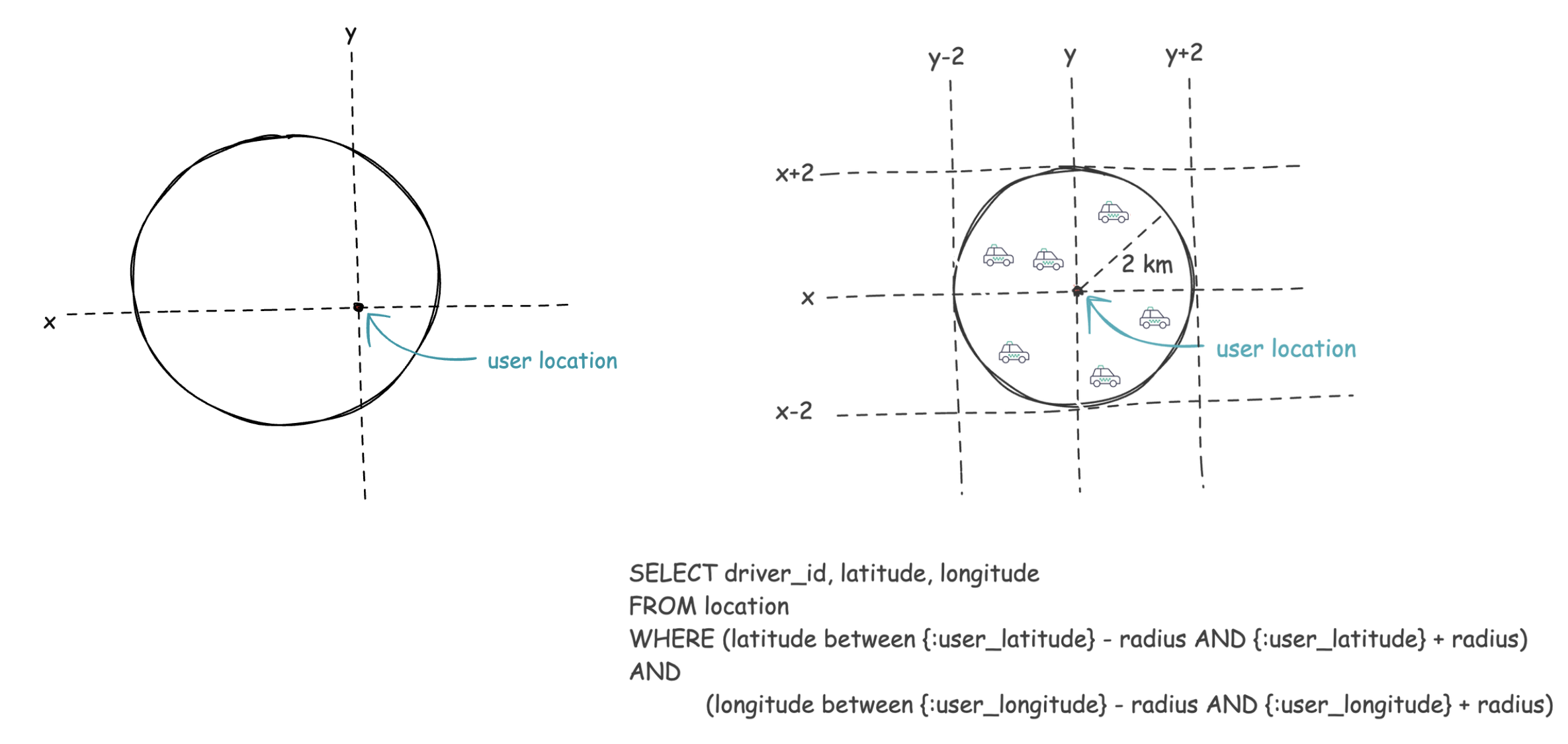
user sends src location let's say the service will find drivers within 2 km range
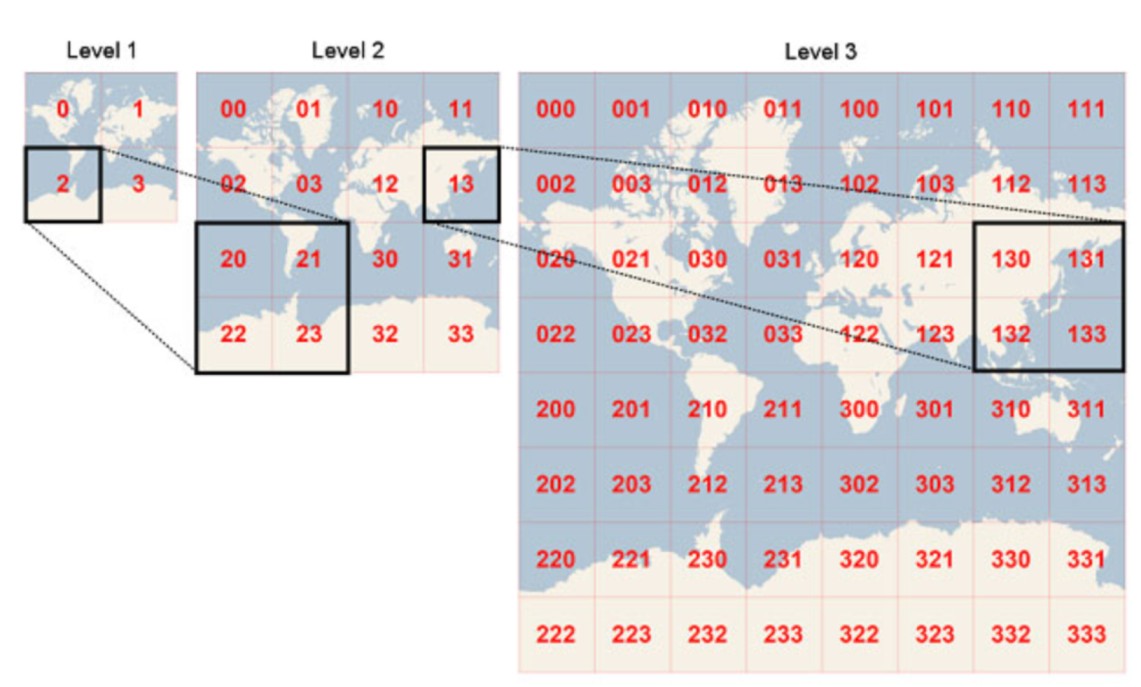
GeoHashing
Quad Tree
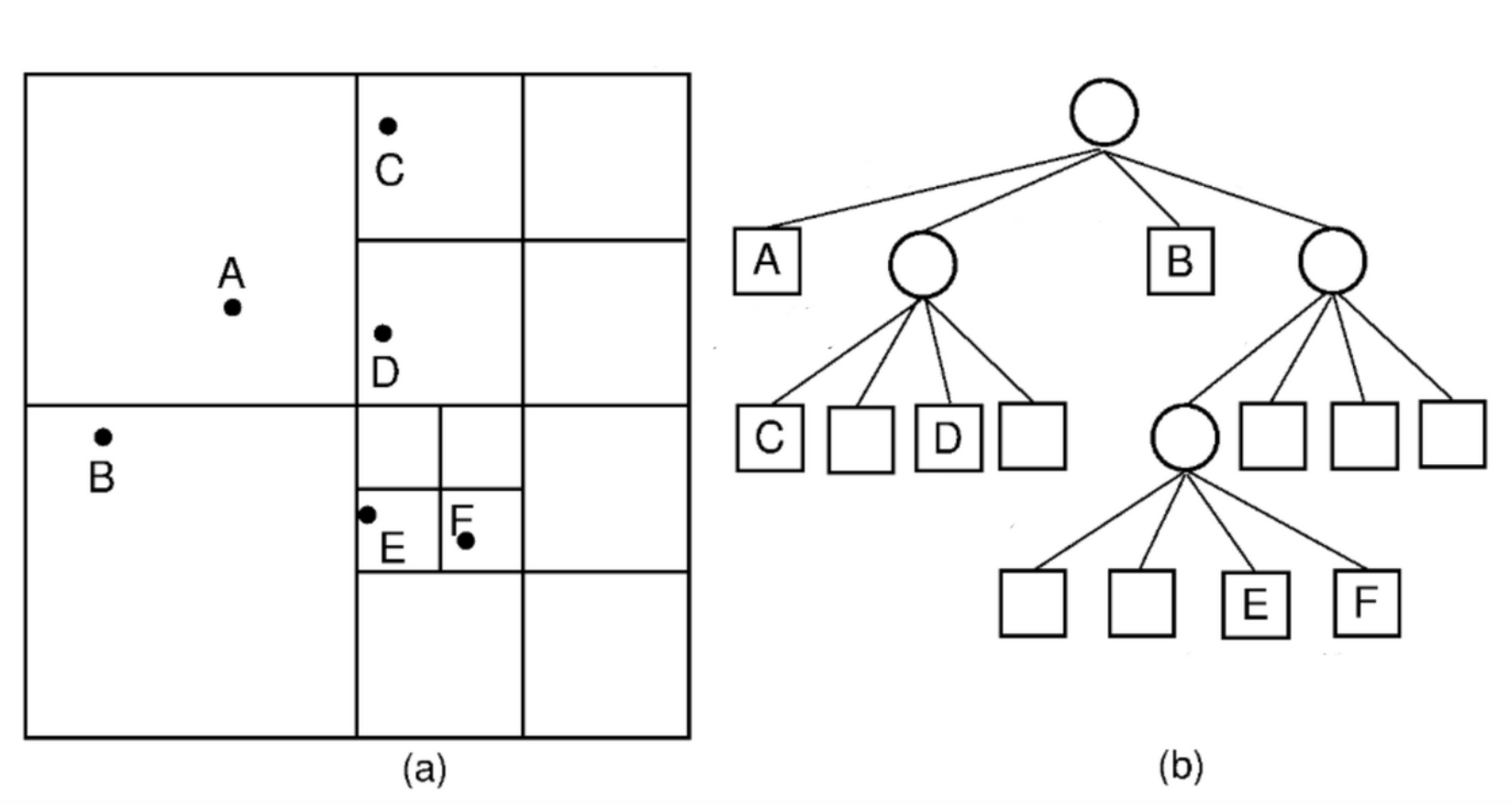
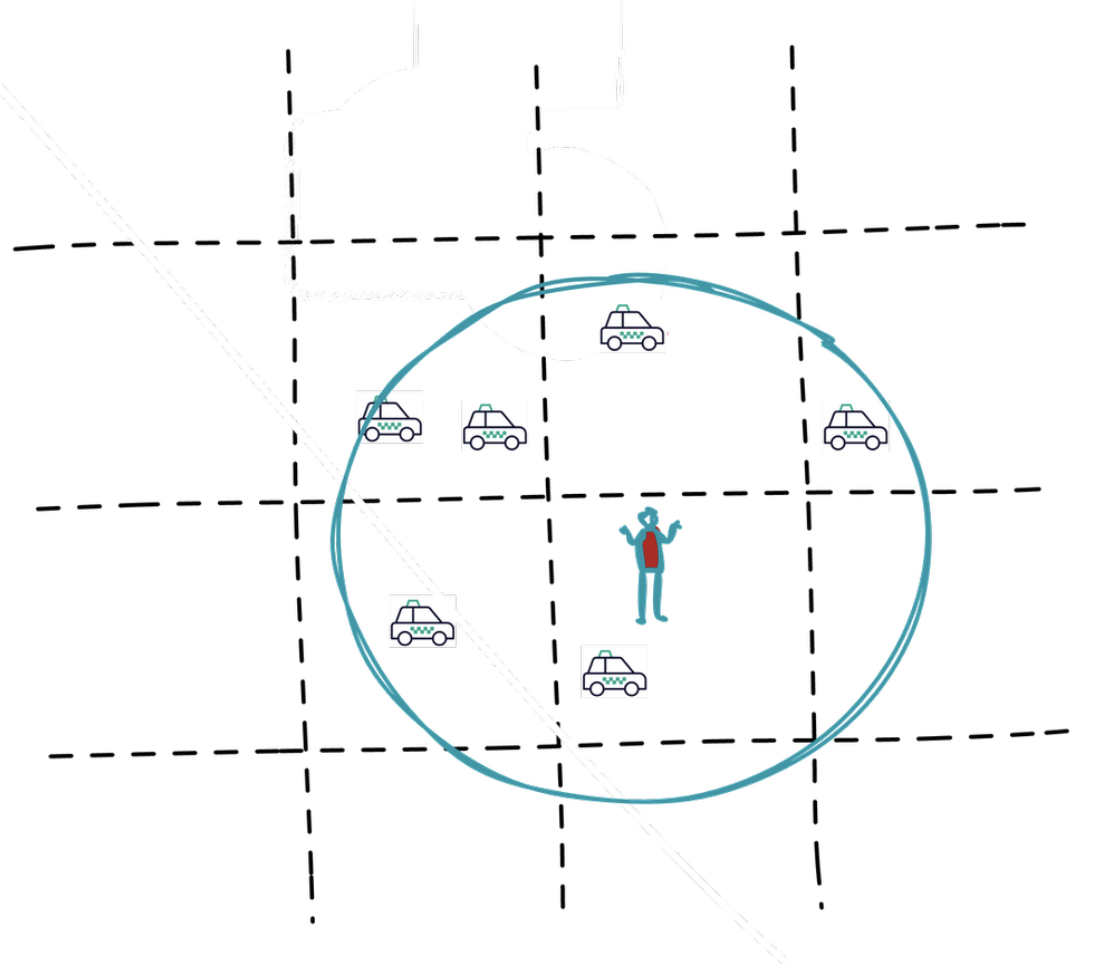
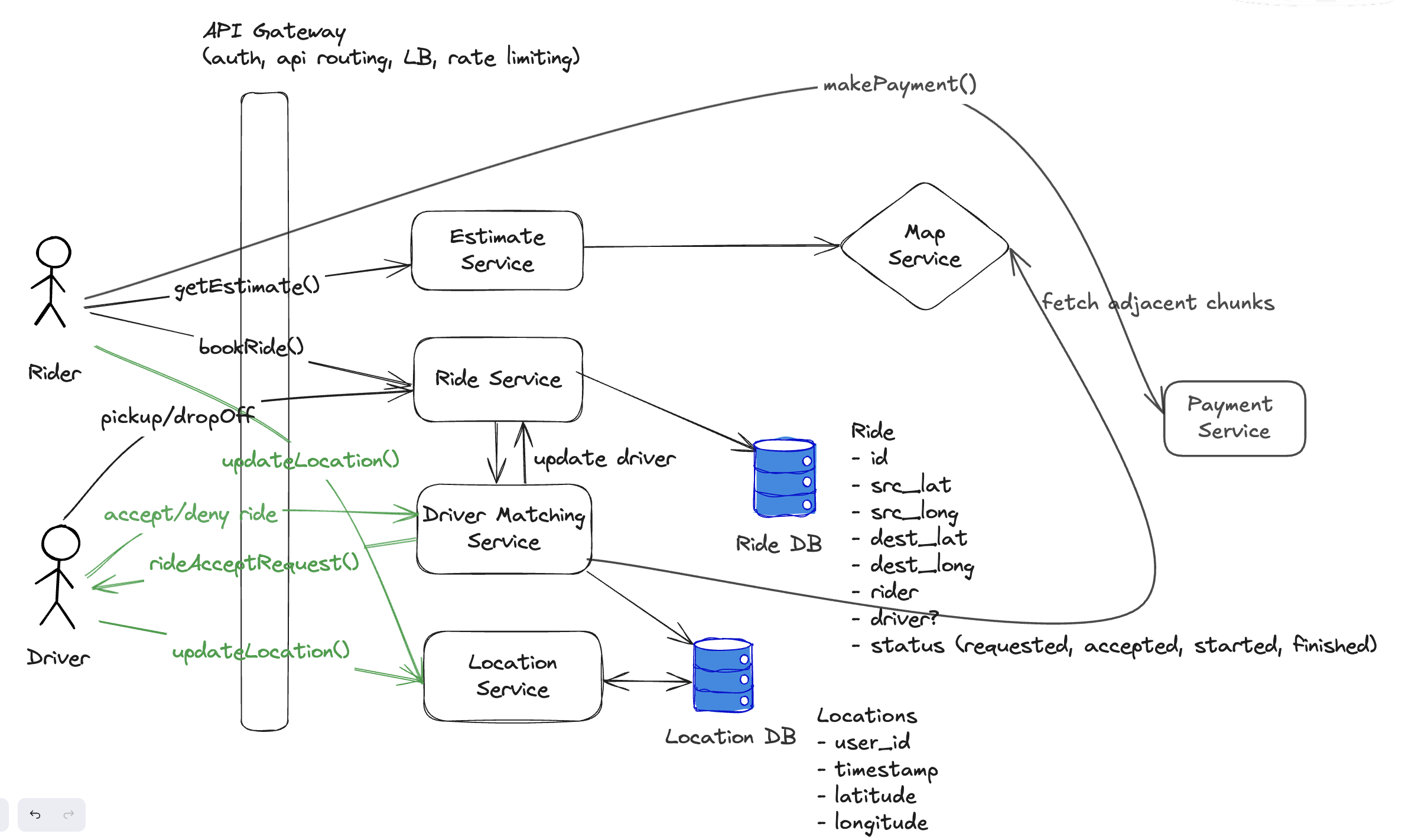
- map service uses some geo hashing/ quad tree indexing
- using ride src location, we get chunk of src from map service
- we get adjacent chunks from map service
- list of drivers fetched from location DB who belongs to those adjacent chunks (order by distance, limit by x)
- Driver matching service sends request to drivers one by one
- one driver rejects, move on to the next one
- if driver accepts, send request to ride service to update the ride details with driver, ride status changed to accepted
- sends notification to user
We have driver locations, but how do we know which chunks they belong to? again take help from map service!!!
How to do proximity search for drivers without using map service?
-
there is lots of overhead in driver matching previous approach
-
lets use a database with geohashing index capability options - POstgres with PostGIS, redis
Can we use redis?
- we just need to store the latest location of drivers in cache
driver_id, lat, long -> 8 bytes *3 => ~ 25bytes for 1 million drivers -> 25 x 10^6 bytes = 25 mb
We can store the latest driver locations in redis -> distributed cache
update location events if we want to store we can use cassanda/dynamodb
Redis supports upto 1 million TPS
- GEOADD, GEOSEARCH -> search within a radius
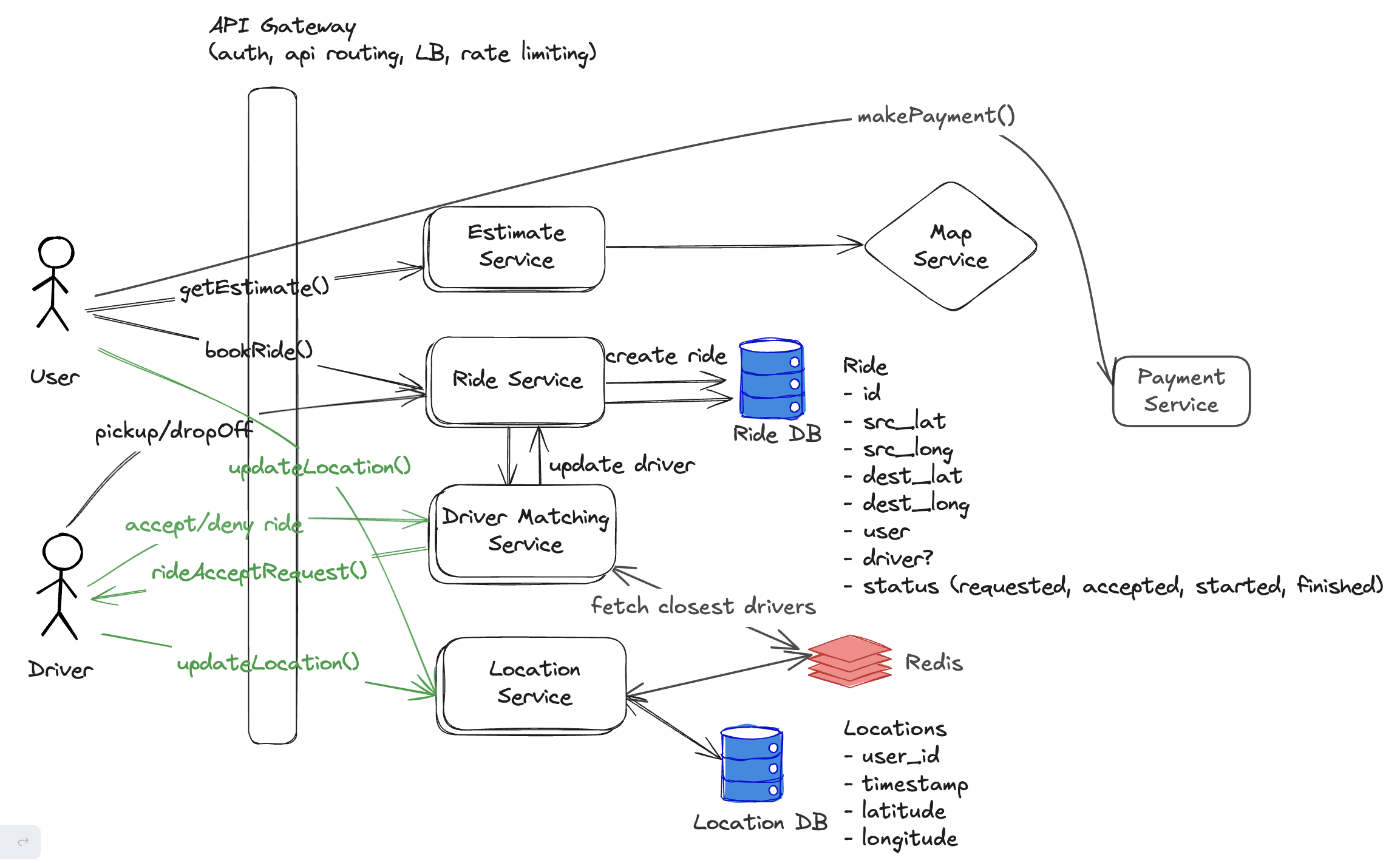
in case of redis failure? distributed - very rare -> have robust monitoring and failover straegies
- system recovers quickly after failure -> as driver sends the location update every 5 seconds
Driver Matching Consistency (No double booking)
one ride multiple drivers?
- we scale the Driver matching service based on rideId (consistent hashing)
- only one server handles one ride
- server sends request to drivers sequentially
- one denies, sends request to the next driver
- so no two drivers will be booked at the same time for one ride
One driver, multiple rides?
-
scaling the Driver matching service based on ride id
-
two ride request went to same service instance
-
both got adjacent driver lists
-
possible that one driver is present in both the lists
-
we dont want to send multiple ride requests to one driver simultaneously, if he accepts => double booking :(
Can we have service instance level lock? one service instance doesnot send requests to one driver for multiple rides simultaneously
- two ride request went to different service instance
- both got adjacent driver lists
- possible that one driver is present in both the lists
- we dont want to send multiple ride requests to one driver simultaneously, if he accepts => double booking :(
service instance level lock on driver with TTL?
- multiple service instance can lock the same driver simultaneously, whats the use of this lock?
- only within a service instance this lock works
Database update for driver status, application level lock TTL?
- update driver status to be outstanding_request
- manage lock in application, if driver accepts update the driver status to accepted or in_ride.
- if driver denies release lock, updates status to be available
what if service instance crashes? driver status remains locked in outstanding_request
Need to run a cron job to find such driver status and clear that out. Extra overhead!!
Distributed lock in Redis with TTL
- driver id locked for say 10s
How do we Scale Ride Service?
- make it stateless, use queue before matching service
How frequently drivers need to send location updates?
- in client we can have adaptive strategy (on device sensor and client algorithm)
- if driver is not moving, dont send updates
- if moving slowly send less frequent updates
How to scale geographically and for peak hours?
-
shard the system geographically
-
GEO sharding, consistent hashing
-
copy of the systems deployed in multiple data centres, with data replication worldwide